机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
访问作者github: https://github.com/NefelibataBIGR/Machine_Learning_Notes ,获取笔记代码
- 深度学习 ⊆ 机器学习 ⊆ 人工智能
- 机器学习是人工智能的一个实现途径
- 深度学习是由机器学习发展而来
- 应用领域:传统预测、图像识别、自然语言处理
- 理论书:《机器学习》“西瓜书”、《统计学习方法》
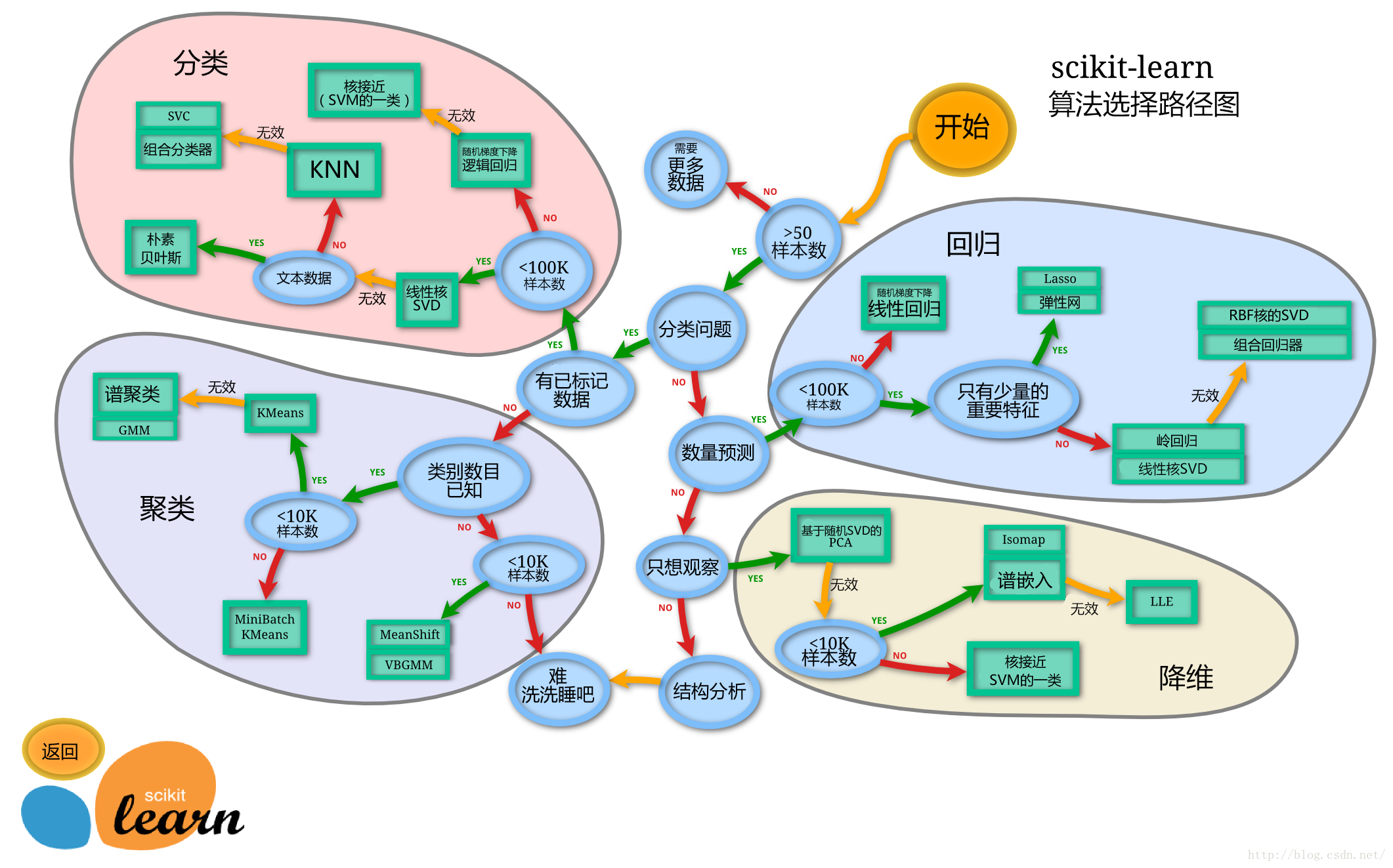
- 库:sklearn
- ==模型选择==:
一、基本概念
- 机器学习:Machine Learning(ML)
- 定义:从数据中自动分析获得模型(规律),并利用模型对未知数据进行预测(解决问题)
- ==算法==是核心,数据和计算是基础
1、数据集的构成
- 结构:特征值+标签值(不一定有)
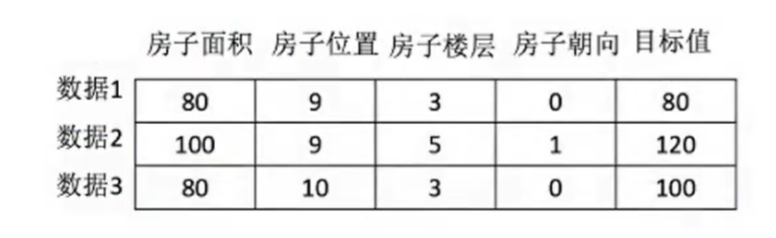
↑通过前四列特征值(x),预测最后一列标签值(y)
每一行称为样本
有些数据集可以没有标签值(聚类、分类)
2、算法的分类
按照标签值是:
- 类别:分类问题
- 连续型数据:回归问题
- 无:无监督学习
分为==监督学习(supervised learning)和无监督学习(unsupervised learning)==
- 监督学习:==分类、回归(有特征值、有标签值)==
- 无监督学习:==聚类(有特征值、无标签值)==
算法:
- 监督学习(预测):
- 分类问题:k-近邻算法、贝叶斯算法、决策树与随机森林、逻辑回归
- 回归问题:线性回归、岭回归
- 无监督学习:
- 聚类:k-means
- 监督学习(预测):
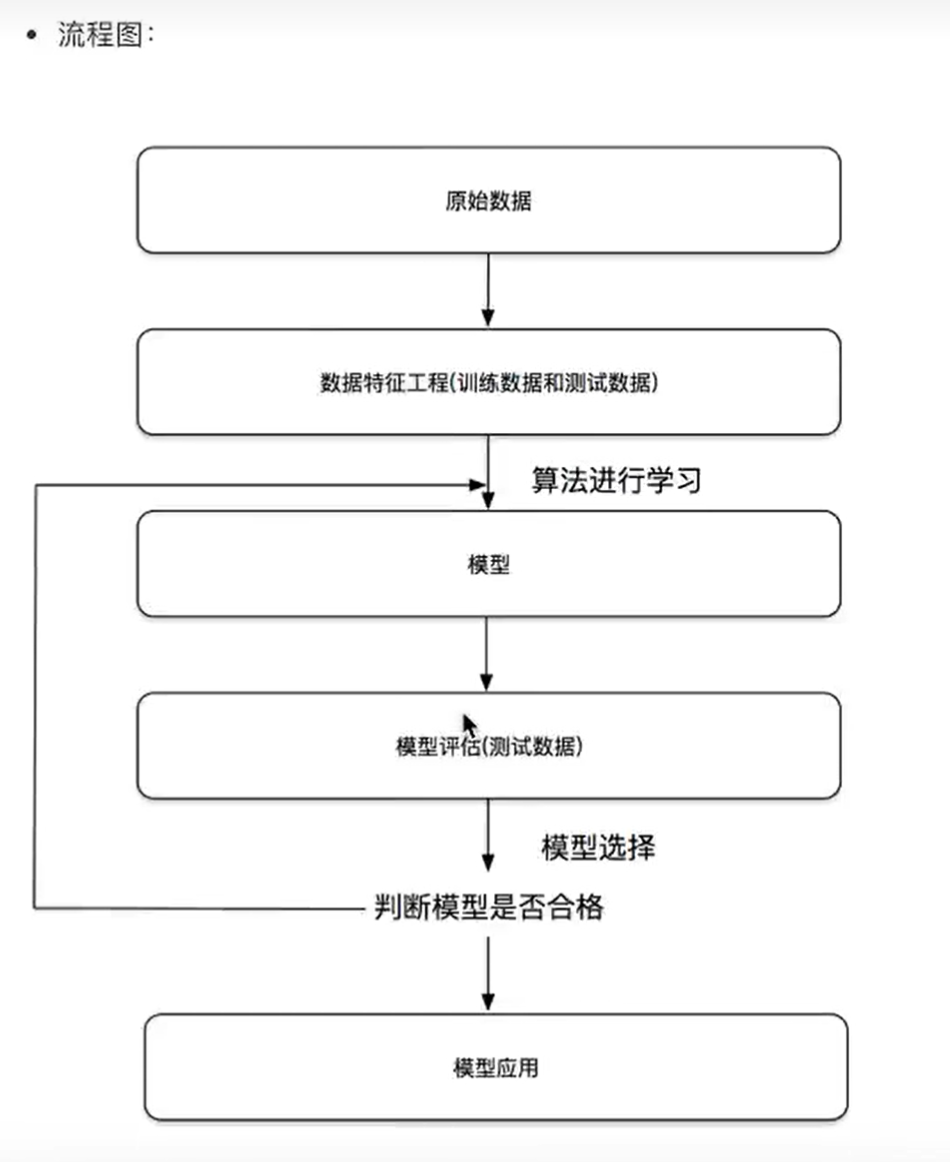
3、开发流程
- 获取数据
- 数据处理
- 特征工程
- 机器学习算法训练,得到模型
- 模型评估(必要时返回第二步再逐步修改)
- 实际应用