机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
访问作者github: https://github.com/NefelibataBIGR/Machine_Learning_Notes ,获取笔记代码
- 深度学习 ⊆ 机器学习 ⊆ 人工智能
- 机器学习是人工智能的一个实现途径
- 深度学习是由机器学习发展而来
- 应用领域:传统预测、图像识别、自然语言处理
- 理论书:《机器学习》“西瓜书”、《统计学习方法》
- 库:sklearn
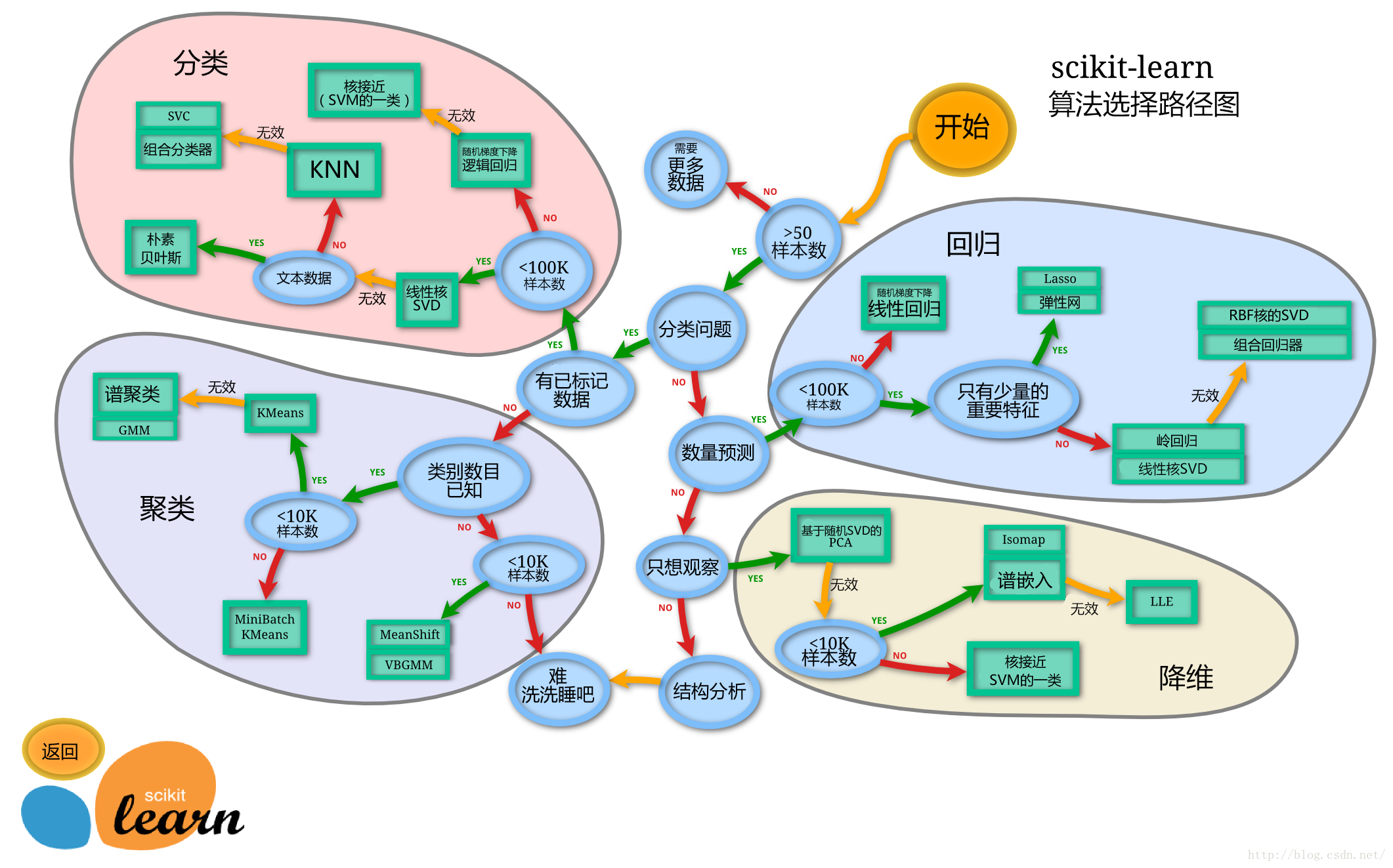
- ==模型选择==:
二、特征工程
具体代码见Python>MachineLearning文件中的==feature_engineering.py==文件
- 训练集和测试集所进行的特征工程应该是相同的,所以对x_test进行特征工程应该用x_train的特征工程处理方法,而不是单独对x_test进行又一次特征工程!
- 同时对一个DataFrame进行多个特征工程操作:sklearn.compose.ColumnTransformer(注意API的中括号与小括号使用)
1、数据集
(1)可用数据集
- 来源:
- 平时:
- 公司内部
- 数据接口
- 机构内部
- 学习:
- sklearn自带少量数据集
- kaggle大量数据集
- UCI 收集的数据集
- 阿里云的天池数据集
- 平时:
(2)Sklearn数据集
- Scikit-learn,Python的机器学习库
- 包含:分类、聚类、回归、特征工程、模型选择与调优
①数据集
- sklearn.datasets(需要import导入)
- 获取方法:
- datasets.load_数据集名字():获取小规模数据集,sklearn自带
- 例如:sklearn.datasets.load_iris(),获取鸢尾花数据集
- datasets.fetch_数据集名字(data_home=数据集下载的目录 , subset= ):获取大规模数据集,需要从网上下载,data_home默认为 ./scikit_learn_data/,subset(可省略)选择需要加载的数据集,有’train’、’test’、’all’
- datasets.load_数据集名字():获取小规模数据集,sklearn自带
②使用
- load和fetch返回的都是Bunch类型的数据(继承自字典)
- 键-值对:
- data:特征值
- target:标签值
- DESCR:数据集的描述
- feature_names:特征值的名字
- target_names:标签值的名字
- 获取属性:
- bunch[‘key’] = value
- bunch.key = value
- 键-值对:
③==划分==
- 数据不能全部用来训练,需要有测试数据集
- 分为:
- 训练数据:构建模型(70~80%)
- 测试数据:评估模型(20~30%)
- sklearn.model_selection.train_test_split(特征值 , 标签值 , test_size= , random_state= )
- 参数(可省略):
- test_size=:测试集的大小比例(如:0.2,默认 0.25)
- random_state=:随机数种子,不同的采样
- return:训练集特征值、测试集特征值、训练集标签值、测试集标签值(注意顺序,可以起名:x_train、x_test、y_train、y_test)
- 参数(可省略):
2、特征工程介绍
- 处理数据,使特征能在算法中发挥更好的作用
- 工具:
- sklearn:特征工程
- pandas:数据清洗、数据处理
3、特征提取
- 将任意数据(如文本、图像等)转换成可用于机器学习算法的数字特征(特征值化)
- 字典特征提取(特征离散化)
- 文本特征提取
- 图像特征提取(深度学习)
(1)对字典特征提取
- 类别 -> one-hot编码
- sklearn.feature_extraction.DictVectorizer(sparse= )
- one-hot编码需要sparse=False,默认sparse=True(也可以sparse=True并对返回的矩阵.toarray(),输出one-hot编码矩阵)
- DictVectorizer.fit_transform(data)
- data为字典的可迭代对象
- return:
- sparse=True -> sparse矩阵(稀疏矩阵):将非零值用位置表示,节省内存
- sparse=False -> one-hot编码的矩阵
- DictVectorizer.get_feature_names_out():获取每一列的名字
data = [{'city': '北京','temperature':100},
{'city': '上海','temperature':60},
{'city': '深圳','temperature':30}] # 数据要是字典的迭代器,可以列表包含字典
# 1、实例化一个转换器类:
trans = DictVectorizer(sparse=False) # one-hot编码需要sparse=False
# 2、调用fit_transform()
data_new = trans.fit_transform(data)
print("new data:\n", data_new)
print("feature names:\n", trans.get_feature_names_out())
返回的one-hot编码的矩阵:
- 应用场景:
- 数据集的类别特征多
- 特征 -> 字典类型
- DictVectorizer
- 拿到的数据是字典类型
- 数据集的类别特征多
(2)对文本特征提取
- 单词作为特征(特征词)
①提取特征词次数
- sklearn.feature_extraction.text.CountVectorizer()
- 可省略参数:stop_words=[ ](不统计的词)
- DictVectorizer.fit_transform(data)
- data为文本或字符串的可迭代对象
- return:sparse矩阵(sparse矩阵.toarray(),输出one-hot编码矩阵)
- return:词频矩阵(单词计数,且去掉字母等无关紧要的字符)
英文文本:
text = ["life is short,i like like python",
"life is too long,i dislike python"]
# 类似dict_demo()
trans = CountVectorizer()
text_new = trans.fit_transform(text)
# print("new text:\n", text_new) # 返回sparse矩阵,不方便观察
print("new text:\n", text_new.toarray())
print("feature names:\n", trans.get_feature_names_out())
返回的one-hot编码的矩阵:
如果是中文文本,导入jieba(结巴)库,用jieba自动分词后再进行类似英文的文本特征提取(见文件)
②提取关键词
关键词:在某一文章中出现多次,其他文章中出现很少,适合用来文章分类
Tf-idf:
- Tf:词频,某个词在给定文章中出现的频率
- Tf = 该文章中词语出现次数/该文章的总词数
- idf:逆向文档频率,一个词的普遍重要性的度量
- idf = lg(语料库中的文章总数 / (含有该词的文章总数+1 ))
- Tf-idf = Tf × idf,可以理解为某词在某文章中的重要程度
- Tf:词频,某个词在给定文章中出现的频率
sklearn.feature_extraction.text.TfidfVectorizer()
- 可省略参数:stop_words=[ ](不统计的词)
- TfidfVectorizer.fit_transform(data)
- data为文本或字符串的可迭代对象
- return:sparse矩阵(sparse矩阵.toarray(),输出one-hot编码矩阵)
- return:词的权重矩阵(数字越大越重要)
4、特征预处理
- 将原始特征数据转换成更适合算法模型的特征数据
- 数值型数据的无量纲化:避免特征间量级的支配影响
- 归一化
- 标准化
- sklearn.preprocessing
(1)归一化
将数据映射到一个区间内(默认 [0 , 1] 区间)

sklearn.preprocessing.MinMaxScaler(feature_range= )
- feature_range=:映射到的区间,默认为(0 , 1)
- MinMaxScaler.fit_transform(data)
- data的格式必须为:ndarray,形状 [样本数 , 特征数]
- return:映射后形状相同的ndarray
缺点:异常值一般是最大值、最小值,所以归一化易受影响,鲁棒性(稳定性)较差(只适合传统精确小数据)
(2)标准化
将数据正态标准化为均值为0,标准差为1的范围内

sklearn.preprocessing.StandardScaler()
- 每列数据转换为均值为0,标准差为1
- StandardScaler.fit_transform(data)
- data的格式必须为:ndarray,形状 [样本数 , 特征数]
- return:转换后形状相同的ndarray
优点:对于有一定数据量的数据集来说,异常值对标准化的影响不大,比较稳定(适合现代嘈杂的大数据环境)
5、特征降维
- 对样本特征矩阵 [样本数 , 特征数] 降维,降低特征个数(列数),特征数就是维度数
- 效果:特征与特征之间不相关
- 相关特征:如 降雨量与相对湿度
- 不相关特征:减少冗余信息
(1)特征选择
- 从原有特征中找出主要特征
- sklearn.feature_selection
①Filter过滤式
- 方法:
方差选择法:过滤掉所有小方差特征
- sklearn.feature_selection.VarianceThreshold(threshold= )
- threshold= :过滤的方差阈值,默认为0
- VarianceThreshold.fit_transform(data)
- data的格式必须为:ndarray,形状 [样本数 , 特征数]
- return:删除低方差特征后的ndarray
- sklearn.feature_selection.VarianceThreshold(threshold= )
相关系数法:过滤掉相关性大的特征( | r | 接近1)
- 皮尔逊相关系数:

- from scipy.stats import pearsonr
- pearsonr(feat1 , feat2)
- feat1、2都是特征列
- return:(相关系数,P_值)(P_越小相关性越大、越显著)
- pearsonr(feat1 , feat2)
- 得到的相关性很高的特征:
- 只选择其中一个
- 加权求和作为新特征替代
- 主成分分析
- 皮尔逊相关系数:
②Embeded嵌入式
- 方法:
- 决策树(见后面章节)
- 正则化(见后面章节)
- 深度学习
(2)主成分分析
- PCA,高维数据 -> 低维数据,可能涉及舍弃数据、增加变量
- 作用:降低维数(复杂度),同时减少信息损失
- 应用:回归分析、聚类分析
- 找到合适的直线,根据投影得出主成分分析结果
- sklearn.decomposition.PCA(n_components= )
- n_components= :
- 小数:保留百分之多少的信息
- 整数:减少到多少特征
- PCA.fit_transform(data)
- data的格式为:二维数组,形状 [样本数 , 特征数]
- return:降维后指定维数(特征数)的ndarray
- n_components= :
- 案例:Instacart市场篮子分析(数据处理部分)
具体代码见Python>MachineLearning文件中的==instacart.ipynb==文件



