机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、算法复杂度理论等多门学科。专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
访问作者github: https://github.com/NefelibataBIGR/Machine_Learning_Notes ,获取笔记代码
- 深度学习 ⊆ 机器学习 ⊆ 人工智能
- 机器学习是人工智能的一个实现途径
- 深度学习是由机器学习发展而来
- 应用领域:传统预测、图像识别、自然语言处理
- 理论书:《机器学习》“西瓜书”、《统计学习方法》
- 库:sklearn
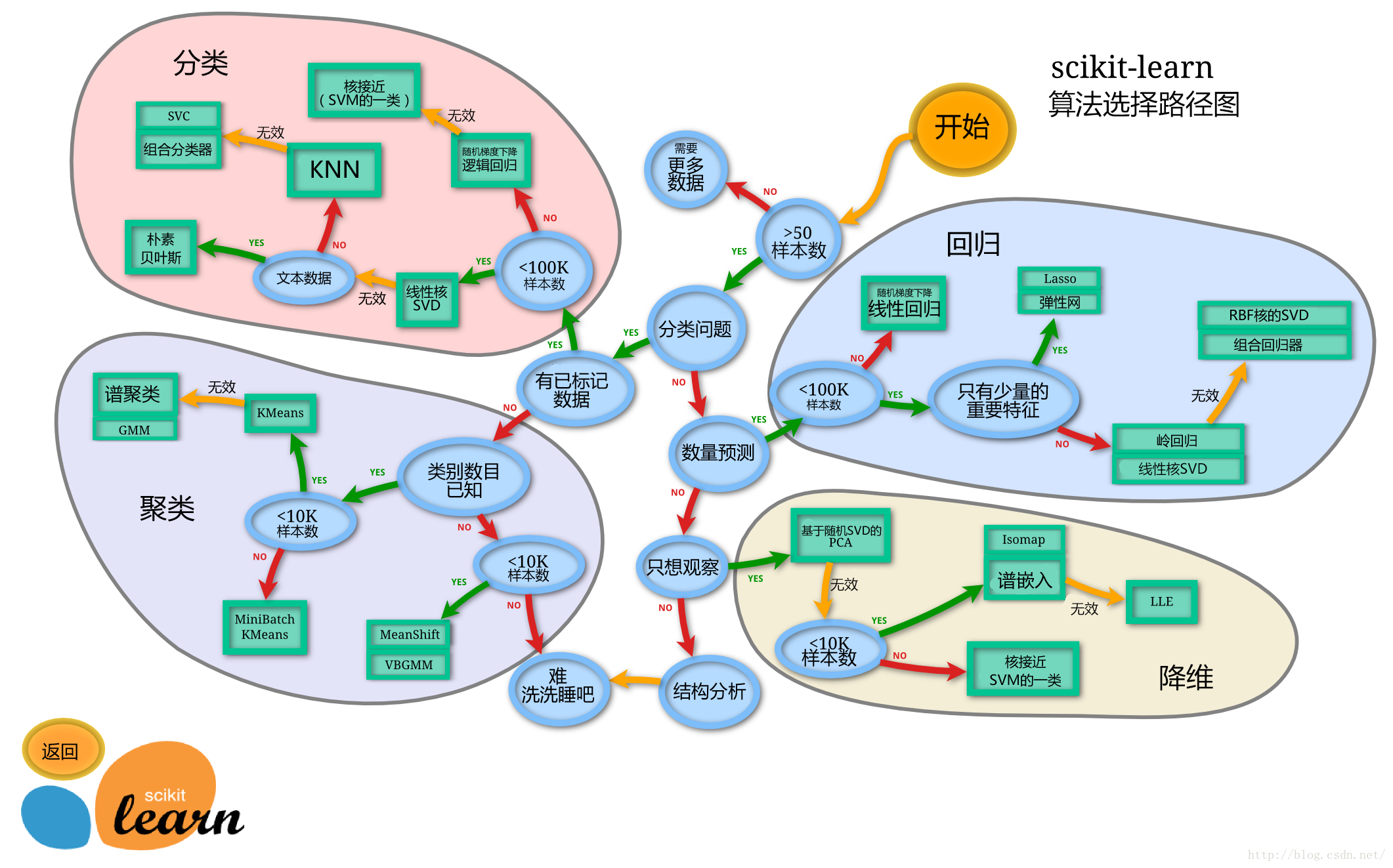
- ==模型选择==:
三、补充:数据预处理
- 数据分为:
- 连续型数据:一个区间内可以取任意值(如:身高、体重等)
- 非连续型数据:只能取某些特定的值(如:性别、民族、血型等)
1、去除唯一属性
- 通常是一些id属性,不能表示数据本身的分布规律
2、处理缺失值
(1)方法
- 直接使用含有缺失值的特征(适用于某个数据比较偏离原始的所有数据)
- 删除含有缺失值的特征(适用于某个特征含有大量缺失值、少量有效值,或含有的缺失值的数据数量相较于总体数据很少,删除影响不大)
- 缺失值插补:均值插补、同类均值插补、建模预测、高维映射、多重插补、手动插补、极大似然估计、压缩感知、矩阵补全
(2)缺失值插补方法
- 均值插补:数据可度量->平均值,不可度量->众数
- 同类均值插补:先分类再用平均值插补
- 建模预测:将缺失值作为预测目标,利用现有的机器学习算法
- 缺点:如果其他属性与缺失值无关,则预测无效;如果相关,则没必要考虑缺失值;一般介于两者之间
- 高维映射:用独热编码(one-hot编码)把属性映射到高维空间
- 优点:最精确
- 缺点:计算量大,所需样本量大
- 多重插补:将缺失值视为一个计算后的值加一个随机噪声,不同噪声得到多个插补值,根据实际情况选择合适的插补值
- 手动插补:主观估计插补值,需要符合现实规律
- 优点:效果比较好
3、数据标准化
- 将某个属性缩放到特定范围
- 原因:某些算法要求数据零均值、单位方差;消除不同属性不同量级的影响
- 方法:
- min-max标准化(归一化):将所有值映射到(0,1)上均匀分布,上下界映射为0、1
- z-score标准化(规范化):(原数据-均值)÷标准差,进行正态分布标准化
四、sklearn转换器和预估器
- 转换器(transformer)、预估器(estimator)
- 转换器用于特征工程、特征处理,预估器用于调用模型、模型训练,注意区分!!!
1、转换器
- 特征工程处理第一步都要实例化一个转换器类,转换器可以看作特征工程方法的父类
- fit_transform():
- fit():输入数据不处理,只计算每一列的均值和标准差
- transform():数据转换,利用fit()得到的均值和标准差计算
2、预估器
- sklearn机器学习算法的实现,可以看作算法的父类
- 分类、回归、无监督学习的所有算法都是estimator的子类
- 步骤:
- 实例化一个预估器(算法)
- 训练,生成模型:调用 算法.fit(x_train , y_train)
- 模型评估:
- 直接比对预测值与真实值:
- y_pred = 算法.predict(x_test)
- y_test == y_pred ?
- 直接计算准确率:
- accuracy = 算法.score(x_test, y_test)
- 直接比对预测值与真实值:
七、模型保存与加载
- 导入库:import joblib
- joblib.dump(estimator , ‘xxx.pkl’):保存模型
- esti = joblib.load(‘xxx.pkl’):加载模型



