访问作者github: https://github.com/NefelibataBIGR/PyTorch_Notes ,获取笔记代码
- 学习内容为小土堆b站pytorch课程
一、课程基础
具体代码见Python>pytorch文件中的==basic_lesson.ipynb==文件
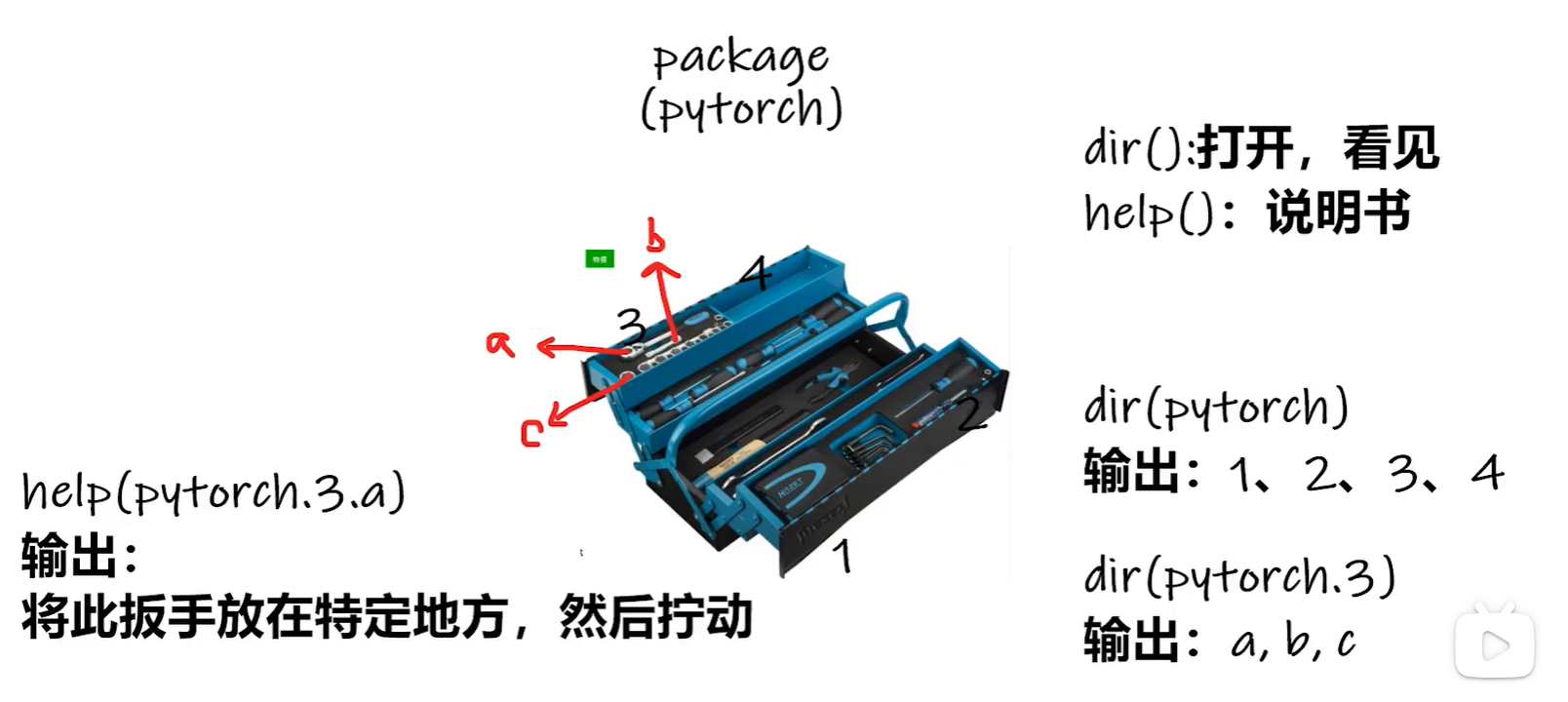
- 两个有用的python函数:dir( )、help( )
import torch
torch.cuda.is_available()
输出 True 即表明 cuda 可用
二、加载数据
具体代码见Python>pytorch文件中的 ==load_data.ipynb== 文件
- Dataset:数据集(含数据+label)
- Dataloader:加载器(设定每次获取数据的batch_size、shuffle等)
1. Dataset
- from torch.utils.data import Dataset
- import os
- 自己设置一个子类继承Dataset类,要能读取数据
class MyData(Dataset):
'''
创建自己的数据集读取类
'''
def __init__(self, root_dir, label_dir): # 定义类里面的全局变量,观察到labels就是文件夹的名称
self.root_dir = root_dir # 根目录,这里是训练集的文件夹路径
self.label_dir = label_dir # 数据集所在文件夹名字,这里是标签名
self.path = os.path.join(self.root_dir, self.label_dir) # 获取图片所在文件,这里文件名就是标签
self.image_path_list = os.listdir(self.path) # 获取所有图片的名字组成列表
def __getitem__(self, index): # 获取某一个图片,index为索引
image_name = self.image_path_list[index]
image_item_path = os.path.join(self.path, image_name)
image = Image.open(image_item_path)
label = self.label_dir
return image, label
def __len__(self): # 返回数据集的长度
return len(self.image_path_list)
具体调试过程见代码文件
2. DataLoader
- from torch.utils.data import DataLoader
- 数据加载器:指定了怎样从Dataset中取数据
- 参考官方文档:torch.utils.data — PyTorch 2.6 documentation
- 参数:
- dataset:要取数据的数据集
- batch_size:每次取的数据数量
- shuffle:顺序是否随机
- num_workers:多进程,=0为主进程
- drop_last:无法整除batch_size时是否舍去余项